【特定健診】健診結果から糖尿病リスクを予測するAIを開発 スマホアプリに搭載し生活改善を促す 大阪大学
2022年10月25日

大阪大学は、機械学習により非常に高い精度で、糖尿病の発症確率を予測できることを、世界ではじめて明らかにしたと発表した。
特定健診のビッグデータを使い、糖尿病・脂質異常症・高血圧の発症確率を高精度で予測するAIモデルを開発。大阪府が運営するスマートフォンアプリ「アスマイル」に搭載したという。
「アスマイル」は、毎日の歩数や体重、血圧などを記録することができ、府民で市町村国保加入者であれば、特定健康診査の結果も自動的に記録される。
「多くの人が日常生活で、事前に数年後の発症確率が分かるようにすれば、各人に行動変容を促し、生活改善に取り組みやすくなります」と、研究者は指摘している。
特定健診の結果から糖尿病の発症確率を高精度で予測
大阪大学は、機械学習が非常に高い精度で糖尿病の発症確率予測に使えることを、世界ではじめて明らかにしたと発表した。 これまでは小規模の健診データしか利用できなかったが、大阪府の協力により、大阪府健診ビッグデータを使用したAIモデルの構築が可能になったとしている。 病気の発症前に個人が発症確率を知ることは、生活スタイル改善の動機付けとなり、個人の努力により病気発症を抑制することが期待できるとしている。 研究は、大阪大学大学院人間科学研究科の瀬戸ひろえ氏、キャンパスライフ健康支援・相談センターの土岐博特任教授らの研究グループによるもの。研究成果は、英科学誌「Scientific Reports」に掲載された。 「本研究成果で、機械学習によって、非常に精度の高い病気発症確率予測のためのAIモデルを開発することが可能であることが判明しました」と、研究グループでは述べている。大阪府民向けスマホアプリに発症確率を予測するAIモデルを搭載
大阪府が提供しているスマホアプリ「アスマイル」に搭載された「健康予測AI」
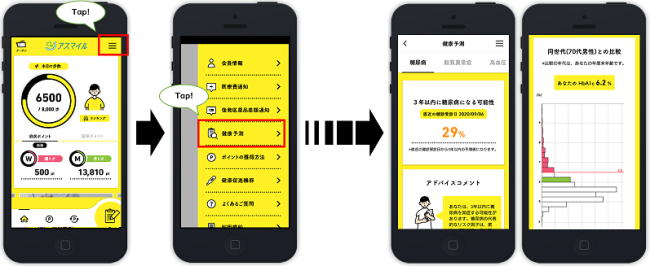
約6年分の大阪府域の市町村国保の保険者の特定健康診査データなどのビッグデータを活用してAIにより構築した、3疾病(2型糖尿病・脂質異常症・高血圧)の直近の健診受診日から3年以内の発症確率を予測するモデル。
健康予測AIは、大阪府が大阪大学キャンパスライフ健康支援・相談センターに委託し開発したもの。
この成果を応用して、3大生活習慣病である糖尿病、脂質異常症、高血圧の発症確率を予測する精度の高いAIモデルを機械学習によって作成し、大阪府が運営するスマートフォンアプリ「アスマイル」に搭載したという。
「アスマイル」は、大阪府民が自律的に健康を推進することを目的に、大阪府が提供しているスマートフォンアプリ。毎日の歩数や体重、血圧などを記録することができ、府民で市町村国保加入者であれば、特定健康診査の結果を「マイナポータル」で閲覧することもできる。
「アスマイル」には、府民の健康増進のための行動変容を促す工夫がさまざまに盛り込まれてある。健康に関わる活動を記録でき、その活動に応じでポイントを貯めることもできる。貯まったポイントに応じて、電子マネーが抽選で当たるなどの特典がある。健康に役立つコラムも提供。
新機能「ウォークラリー」も2022年10月から搭載した。アプリに掲載されるウォーキングコースを選んでもらい、コース中に設定されたすべての「チェックイン地点」をタップするとポイントをもらえる。
「多くの人が日常生活のなかで、事前に数年後の生活習慣病の発症確率を知ることができるようにして、各人が自律的に健康を維持するような生活習慣病改善の重要な道具となることが期待されます」としている。
健康予測AIは、大阪府が大阪大学キャンパスライフ健康支援・相談センターに委託し開発したもの。
大阪府国保の約60万人分のビッグデータを活用
これまで、糖尿病などの病気発症確率予測は、古典的統計モデルであるロジスティック回帰モデルと機械学習を用いたAIモデルにはその発症予測の精度で差異はないと考えられていた。 病気の発症予測を精度良く行うために、多くの人々の健診結果を使う必要があるものの、個人情報であることからデータの入手や活用が困難だった。 これまでは、モデル構築を行うための人数(サンプルサイズ)が少なく、機械学習モデルの予測精度を検証するための十分なデータ数が集まらないという課題があった。 そこで土岐特任教授らの研究グループは、大阪府国保連合会保有の国民健康保険被保険者の健診結果データ(年間で約60万人分のビッグデータ)を活用し、糖尿病の発症予測について、1万件を超えるビッグデータでの機械学習の優位性を定量化し、機械学習が健康予測に高精度で適用できることを解明した。
2型糖尿病の発症予測では機械学習が良い精度を出すことが示された
予測値と計測値の違いを表す指標である誤差因子ECEをサンプルサイズの関数で図示
誤差はサンプルサイズが1万を超えるところから顕著に差があらわれた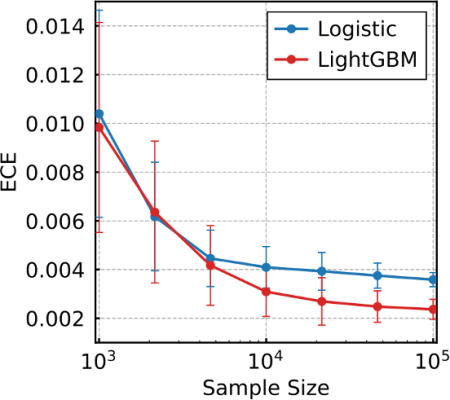
予測値と計測値の違いを表す指標である誤差因子ECEをサンプルサイズの関数で図示
誤差はサンプルサイズが1万を超えるところから顕著に差があらわれた
出典:大阪大学、2022年
サンプルサイズが1万を超えると機械学習の精度が上がる
研究グループは、大阪府国保連合会および大阪府保険者協議会の協力で、個人が特定できないように加工された国民健康保険被保険者の健診結果データなどを取得。このうち、糖尿病の発症予測モデルを構築するための対象者を抽出した結果、約28万人の国保被保険者が対象となった。 そこからさまざまなサンプルサイズでデータを抽出し、サンプルサイズを変化させたときに、どれだけの精度で予測確率が推定できるか検証した。計算の誤差は、サンプルサイズが1万を超えるところから顕著に差があらわれ、機械学習が良い精度を出すことが示された。 これらの計算には、勾配ブースティング決定木という高度に発展させた決定木の方法を用いた。これは、決定木を複数組み合わせることで予測精度を向上させる機械学習モデルのひとつ。 このモデルでは、プログラミング言語で効率良く計算を行えるPythonで実行可能なLightGBMを利用することで高速な計算が可能となる。LightGBMは、計算時間のかかる勾配ブースティング決定木を高度化・高速化した機械学習ソフトウェア。 機械学習のパラメータを決定するのは難しく、何度も計算が必要だが、このソフトにはパラメータチューニングを効率的に行うパッケージもあり、最近では多くの研究に利用されている。研究グループは、ビッグデータを使った数値計算を何度も繰り返すことが可能であったことも重要と指摘している。 大阪大学大学院人間科学研究科大阪大学キャンパスライフ健康支援・相談センター
Gradient boosting decision tree becomes more reliable than logistic regression in predicting probability for diabetes with big data (Scientific Reports 2022年10月11日) おおさか健活マイレージ アスマイルについて (大阪府)
ビッグデータを活用した健康予測AI等をアスマイルへ搭載します! (大阪府)
記事の内容は掲載日時点のものです。
本サイトに掲載されている記事・写真・図表の無断転載を禁じます。
本サイトに掲載されている記事・写真・図表の無断転載を禁じます。


